Lab 5 Reflection
BUAA 2023 Spring OS
Prologue
In this lab, we finally come to File System. For MOS, a micro-kernel OS, file system serves as a process in user space, and all file operations are done via IPC between user process and this file system process. As we introduce file system to our OS, we have to deal with disk. Thus there is another part of code to handle memory and disk.
Tips for Windows Players
If you do labs on Windows with Visual Studio and WSL, you may encounter some subtle errors. Expand this part if your seek for solutions. 🙃
Visual Studio Tips
You may encounter an error saying that DT_DIR is undefined. It may not be a problem when you compile the project, but IntelliSense will show this as an error. Expand it if you have such
The reason is that, though with WSL, our code is on Windows, and we use MinGW (Minimal GNU for Windows). This macro is defined in standard dirent.h header file, but surrounded with a #if macro. Of course, _WIN32 is not defined since our OS will be compiled on Linux. But _BSD_SOURCE is not defined neither! 😵💫
1 | // dirent.h |
So, the solution is that, in the CppProperties.json, add defines entry in configurations with _BSD_SOURCE declared. The rest of the properties are omitted. This works only as a reminder to Visual Studio IntelliSense, so won’t have actual effect on our compilation and run.
1 | { |
If you don’t know what is
CppProperties.jsonis, please refer to my previous post.
Warning
For Windows, the EOL (End of line) symbol is CRLF (\r\n), while for Linux, it is LF (\n). In this lab, you have to pay attention to this subtle difference, for it may cause slight errors. For example, the string in our code is “hello\n”, but in the file, it is “hello\r\n” if you accept the default CRLF on Windows. So, when doing string compare, these two strings will not match each other, while they should.
Files you should especially pay attention to are tests/lab5_2/newmotd and tests/lab5_2/motd.
You can also refer to this post to change default EOL when saving a file: Encodings and line endings.
1. Disk Access
The purpose of the File System is to make memory persistent. But our RAM is not persistent. So before we formally introduce File System, we have to get pass hard disk.
1.1 Device
Disk, the same as all other devices, are accessed though the register it provides, and these registers are mapped to our kernel memory. So we can manipulate them by read and write certain memory range.
In include/mmu.h, we can see the memory layout of MOS. And you can find that devices are mapped to kseg1.

I think now it is a good time for us to review memory accessing process.
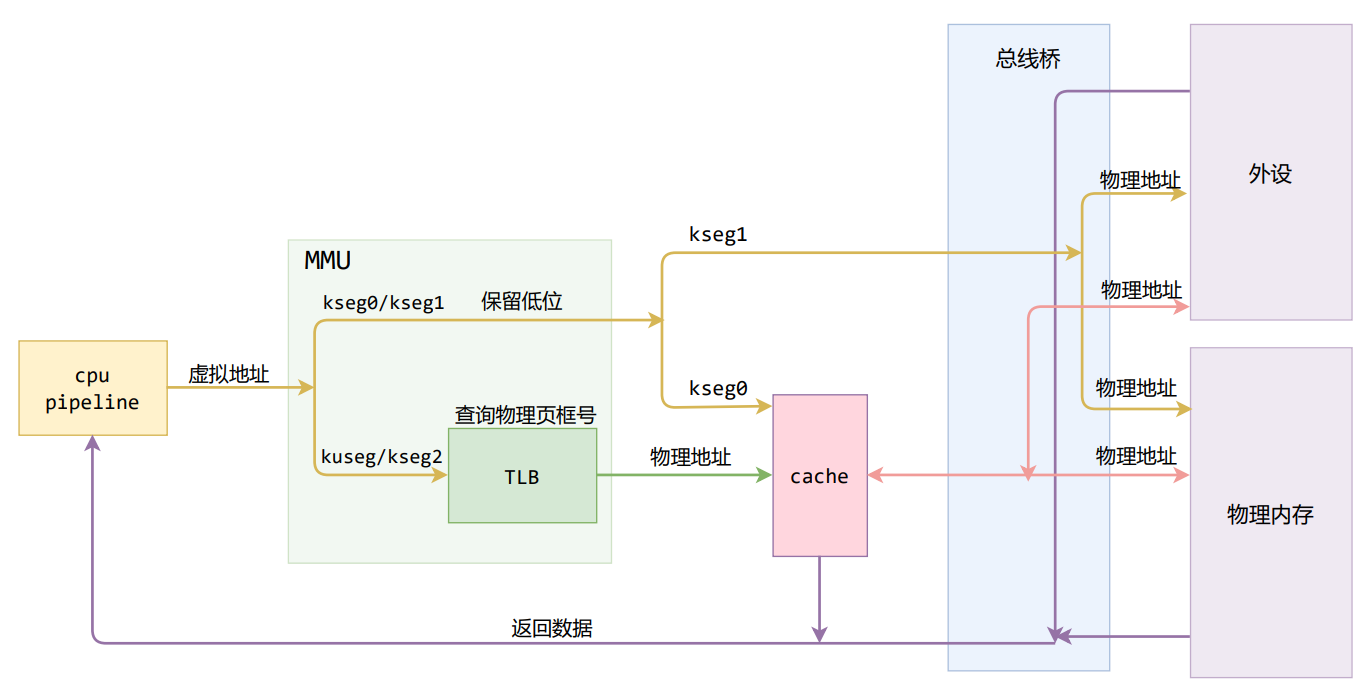
You can see that kseg1 is the only segment that doesn’t go though cache. Ya know, you just cannot cache the input or output of keyboard, or any other devices.
1.2 Read & Write Device Segment
Now that we have to communicate with device by read and write kseg1, it is time to write such functions to do this job.
Just like when we access kernel address using
KADDRandPADDR, here, we also need such conversion between device address and its correspondent inkseg1. It can be really simple like this.
As we know, such operations are done via system call. So here is the system call. va is the address of the value we want to write into or read out of the device located at address pa. And len is the length of data we want.
1 | // kern/syscall_all.c |
For MOS, we have the following there devices, and they are fixed to certain physical addresses. The detailed info for them are defined in corresponding header files.
| Device | Start Address | Length | Header File |
|---|---|---|---|
| Console | 0x10000000 | 0x20 | include/drivers/dev_cons.h |
| IDE Disk | 0x13000000 | 0x4200 | include/drivers/dev_disk.h |
| RTC | 0x15000000 | 0x200 | include/drivers/dev_rtc.h |
sys_write/read_dev
Before we read and write, we must validate address first.
Validate Address
First, since File System runs in user space, the va is limited to user space only. So we can simply check it by verify if it is in user space range.
1 | static inline int is_illegal_va_range(u_long va, u_int len) |
Then, it is the physical address of device. Here I added a auxiliary range check function. For device address, we must make sure it is within one of the device memory range mentioned above.
1 | static inline int in_range(u_long base, u_int range, u_long begin, u_int len) |
After address validation, we can read and write device as we will. Just use memcpy for memory exchange.
1 | int sys_write_dev(u_int va, u_int pa, u_int len) |
Just notice that pa is the physical address, and we have to add kseg1 offset to it.
1.3 IDE Read & Write
With sys_read_dev and sys_write_dev, we can communicate with device by read and write corresponding memory range. So it is time to really read and write data from disk. IDE (Integrated Drive Electronics) is a old-fashioned disk interface.
1.3.1 IDE Interface
Disk, you know, that structure. A disk is divided in to many sectors, and we can only get one, and only one sector by one read or write operation. The address information about our IDE disk in MOS is as follows. The base address of IDE disk is 0x13000000, defined by macro DEV_DISK_ADDRESS. All offset below are based on this.
| Offset | Macro | Description | Data Bytes |
|---|---|---|---|
| 0x0000 | DEV_DISK_OFFSET |
read/write offset to the 0 address of disk | 4 |
| 0x0008 | DEV_DISK_OFFSET_HIGH32 |
high 32 bits of read/write offset | 4 |
| 0x0010 | DEV_DISK_ID |
the ID of the disk to operate | 4 |
| 0x0020 | DEV_DISK_START_OPERATION |
set the disk to start read/write operation | 4 |
| 0x0030 | DEV_DISK_STATUS |
return status of disk | 4 |
| 0x4000 | DEV_DISK_BUFFER |
buffer with the size of a sector | 512 |
Disk is large, so 4 bytes of 4G memory range may be not enough. So you can use high 32 bit to manipulate on larger memory.
Often, we may have more than one disk, so we should specify which disk to operate. But here in MOS, we only have one, whose ID is, of course, 0.
DEV_DISK_START_OPERATION indicates the following operation is a read or write. It is either DEV_DISK_OPERATION_READ or DEV_DISK_OPERATION_WRITE.
DEV_DISK_STATUS will store the return value of the disk operation. Just read the value from this memory. 0 indicates error.
DEV_DISK_BUFFER, well, it is literally the buffer that store the content of a sector, whether it will be written into or loaded from the disk.
1.3.2 IDE Operation
As we’re familiar with IDE Interface, we can now read and write data through it. Notice that, whenever we read or write, we do this one sector a time. Here is the declaration of read and write operation. You can see that we do these sector by sector.
1 | // fs/serv.h |
You may notice that these are put in serv.h, which is the header file for File System process. Well, this perhaps because that disk operation is needed for File System.
To set or read registers or buffer, we can simple use the functions we wrote in 1.2. So it can be relatively easy.
ide_read/write
The detailed process of read/write IDE disk is that, set disk ID and offset first, then begin read or write, and at last, get the return value. Just notice that, the order of start operation and prepare buffer memory is different. Since we have to fill buffer before we write it into the disk, and we can only get the valid memory after we read it from the disk.
1 | void ide_read(u_int diskno, u_int secno, void* dst, u_int nsecs) |
Well, we cannot handle disk hardware error, so we simply panic on any error.
Tips: Here, we should use
user_panic, rather thanpanic. Since the latter one is for kernel.
2. File System
2.1 Disk Layout
The basic unit in disk is sector, as we already know. But a sector is only of 512 bytes, which is a little small, thus will make too many of them. So the File System merge multiple sectors into one block as the basic unit for Operating System. Usually, one block is of the same size as page.
There are some macros in MOS for such conversions.
2
3
4
5
6
// fs/serv.h
And it is easy to imagine the layout of those blocks. Later, when we read or write disk, we always read or write a complete block, i.e. read or write multiple sectors in a row.

Block 0 stores the bootloader, and partition table of the disk. Super block stores the key information about the disk - the magic number, number of blocks and root directory. By reading this, our File System can know the general information about the blocks.
1 | // user/include/fs.h |
And the following several blocks are bitmap blocks. The number of it depends on the size of the disk. If there are N blocks, then there must be enough bitmap blocks to hold these N bits. You can get it by a simple division, just make sure there are enough bits.
1 | nbitblock = (NBLOCK + BIT2BLK - 1) / BIT2BLK; |
2.2 Block Cache in Memory
In MOS, there is a wired design, I think, that map disk blocks to File System process’s memory. And here is how this is done.

As you can see, we mapped disk to memory block by block. Now you can see why I say wired, because it will limit our disk size to 1GB only. 😢
There are two macros for this mapping that indicate the address range for such cache.
2
3
Such mapping is quite easy, as it is one-to-one. So we just add a offset to block ID (bno/blockno in code) to convert it into corresponding virtual address. So we have this function.
1 | void* diskaddr(u_int blockno); |
diskaddr
Just remember to validate address range.
1 | void* diskaddr(u_int blockno) |
Things become easier as block and page are of the same size. When we cache a block, we simple get its virtual address in memory via diskaddr function, and then allocate a page to store it.
2.3 Block Management
The fundamental work for File System is to manage all these blocks. As we know, it uses bitmap to record the use of blocks, so the basic mechanism is clear and set corresponding bits. And of course, allocate and free blocks when necessary.
2.3.1 Block Initialization
All these are actually done in File System process. So let’s have a brief look at it. Here is its main function.
1 | // fs/serv.c |
We can see that, it first initialize it self, then initialize File System, and at last, serve as File System. Here, we just need to know fs_init.
1 | // fs/serv/c |
Still, is separated into small tasks. First one is to read the Super block to get block info. Then, I think, is a self diagnose, read it as you will. And the last one is to read the bitmap block to get the current disk usage.
read_bitmap
Related functions will be introduced later. 😉
1 | // fs/fs.c |
2.3.2 Block Mapping
As mentioned above, we cache blocks in memory, so we have to maintain such mapping. It involves these two functions below. Mapping block is actually allocating a page for the block, and link it virtual address to the page.
1 | // fs/serv.h |
Actually, in Lab 5,
unmap_blockis not declared infs/serv.h. They are intests/lab5_3/mix_check.c. Err… And in our File System, we don’t yet use it. Perhaps not the time?
Before we handle these functions, let’s take a look at some auxiliary functions.
1 | // fs/serv.c |
In bitmap, 1 represents free state.
block_is_xxx
1 | // fs/serv.c |
bitmapis au_intarray, one unit in bitmap is 4 Bytes, 32 bits. Oneu_intcan store 32 bits, so that’s what 32 means here.
Actually the mapping status of block can be presented by that of the virtual address it corresponds to.
1 | int va_is_mapped(void* va) |
With these auxiliary functions, it would be easy to map blocks.
map_block
1 | int map_block(u_int blockno) |
2.3.3 Block Allocation
Then, we got to handle block allocation. Here are the declaration of related functions. Just allocate and free, huh?
1 | // fs/serv.h |
The same as
unmap_block,free_blockis also declared intests/lab5_3/mix_check.cwith the same reason I guessed.
To allocate a block, we have to traverse all blocks to find the first free block, because we want to make use of limited number of blocks. Then, we just modify the bitmap block to mark it allocated.
Important! As we modified the bitmap block, we got to write it back to the disk to make the change persistent.
There are two steps in alloc_block. First, we should allocate a block, just allocate one by marking it allocated. Then, we use map_block to map it to its virtual address.
alloc_block
1 | int alloc_block(void) |
free_block is relatively simpler. Since here we cache blocks, so there’s no need to free the page. We can reuse the page next time.
free_block
1 | void free_block(u_int blockno) |
2.3.4 Read & Write Block
Finally, we just need to read and write block to finish this part.
1 | // fs/fs.c |
read/write_block
1 | // fs/fs.c |
2.4 File Layout
2.4.1 File & Block
Although block is fundamental for File System, users cannot accept such low level concept. So we use files to cover all these ugly stuffs. Here is a good figure to show the mechanism of how file covers block.

Since the blocks are stored as type
struct Block, we can simple access them by subscription, so instruct File, we can only record the index of the block it has.File::f_indirectuses a block if necessary to store more direct links. We can get the number of blocks of a file using its size. Let’s assume there is aFile* file.
Then we could have this conversion from file block id to disk block id. To make it easier, we simply omitted the first 10 (
NDIRECT) links in the indirect block to make file block id continuous. Thus we could have such code.
2
3
4
bno = file->f_direct[i];
else
bno = ((uint32_t*)blocks[file->f_indirect])[i];Notice: These two are just pseudo-code.
And here is the actual declaration of file.
struct File
This is in fs/fs.h.
1 | // Maximum size of a filename (a single path component), including null. |
We can see that, there are 1024 (NINDIRECT) links available, which means a file can have at most 1024 blocks. Thus the maximum file size our MOS can handle is 4M.
Notice: It seems, our filename is the absolute path name. 😧
ℹ If you want to know how exactly we get disk block id from file block id, hold your horse! I’ll talk about them in 2.4.4. 🙂
2.4.2 File Descriptor
In Linux, when we open a file using UNIX style open, we will get a file descriptor representing the file we opened. The same goes with MOS. Let’s see its definition.
1 | // user/include/fd.h |
struct Fd is the basic description of a file, it indicate the file is a regular file, a console or a pipe, and some basic information. Then, struct Filefd is the specific descriptor for file.
We arrange an area in the memory for file descriptor and file content, and they can be accessed via a simple conversion. Here is the layout of file descriptor and content in a process’ memory.

Important! Now we’ve had this layout in our mind. Remember, the address in file descriptor table is the same as the address of
struct Fdandstruct Filefd. So… Did you notice that? The first member instruct Filefdis juststruct Fd, which means we can simply apply force conversion between them, or get them directly from the virtual address.
In MOS, we support at most 32 (MAXFD) file descriptors for one process. We want to make file descriptor table to take up a whole page directory, so we just make it a 4 MB segment. We assign 4 KB for each struct Filefd, and each of them corresponds to a 4 MB size segment as the content of the file. The conversion can be simple.
1 | // user/lib/fd.h |
So when we open a file, we first prepare the file descriptor, then map the file to its 4 MB segment.
Previously, we know that MOS can only handle 4 MB file. So this is enough.
2.4.3 Allocate & Free File Descriptor
Well, the arrangement of these two function is not that pleasing. Perhaps due the the use of them. fd_alloc is used by more functions when opening different devices, while close can handle all devices.
1 | // user/include/fd.h |
When we allocate a file descriptor, we only find the first empty 4 KB segment, and return its virtual address. We do not allocate page for it yet! The page allocation will be done later when initialize the descriptor by File System process. So when we close a file descriptor, we simple un-map the page from the virtual address.
fd_alloc/close
1 | int fd_alloc(struct Fd** fd) |
One more thing, when we want to look up a file descriptor, we use the id of the file descriptor (what we get from fd2num). We cannot find the file descriptor immediately after fd_alloc, since then, no actual page is allocated. We can only get it after File System initialized it for us.
fd_lookup
1 | int fd_lookup(int fdnum, struct Fd** fd) |
2.4.4 Traverse File Blocks
We can use file_block_walk to get the corresponding disk block id of the given file block id. This one is quite similar to its peer pgdir_walk. And we wrap it to do the conversion from file block id to disk block id as file_map_block.
1 | // fs/fs.c |
file_map_block
1 | // fs/fs.c |
file_block_walk
1 | int file_block_walk(struct File* f, u_int filebno, uint32_t** ppdiskbno, u_int alloc) |
I just don’t understand why here we pass
diskbnoas a double-pointer, which, obviously, can be done via a simple pointer. ☹️
Similarly, we have file_get_block to directly get the block content from its file block id.
1 | // fs/serv.h |
file_get_block
1 | // fs/fs.c |
2.5 File Operations
Finally, we should provide interface for user processes to manipulate files. All our file operation are handed to File System process via IPC, and File System will do all stuffs for us and deliver necessary data back to us. Here I just list some of them.
1 | // user/include/lib.h |
For more information on how File System process handle these requests, please refer to may another post.
File operations are provided to users by library functions, such as open and close, read and write.
2.5.1 Device Interface
After we open a file, or to be more general, open a device, we can just do many operations just using device, instead of by requesting File System. We have three types of devices, and each can be represented by a Device structure. Are we getting it? We are using function pointers to achieve polymorphism.
1 | struct Dev |
Then we have these three devices.
1 | extern struct Dev devcons; |
Then, let’s see how devfile is initialized. So the problem now is how these concrete functions are implemented.
1 | struct Dev devfile = { |
file_read reads n bytes from the given file from given offset.
file_read
1 | static int file_read(struct Fd* fd, void* buf, u_int n, u_int offset) |
file_write is similar to its read brother.
file_write
Generally, there is not much difference, but for write, we have to enlarge the file when necessary.
1 | static int file_write(struct Fd* fd, const void* buf, u_int n, u_int offset) |
When we close a file, we first should mark it dirty to save any changes back to the disk. Then, we just un-map its corresponding virtual address.
file_close
1 | int file_close(struct Fd* fd) |
Well, there’s not much to say about file_stat, it just get the statistics of a file.
file_stat
1 | static int file_stat(struct Fd* fd, struct Stat* st) |
2.5.2 Library Interface
We cannot let users manipulate device directly, so we hide those details and provide some library interface for them. For the functions mentioned in 2.5.1, we have corresponding library functions for each of them.
1 | // user/include/lib.h |
close
1 | int close(int fdnum) |
ℹ This is a little special, please refer to File System IPC for more information. 😙
read
1 | int read(int fdnum, void* buf, u_int n) |
write
1 | int write(int fdnum, const void* buf, u_int n) |
stat
1 | int stat(const char* path, struct Stat* stat) |
2.5.3 Open & Close a File
Above is operations after we open a file. But, we have to open it first. So… ? 🫤 Let’s open it. The opening process can be divided into several steps.
- Allocate a page for file description. As stated above, we simple get a candidate virtual address and do nothing to it. So if we do this again, we’ll get the same virtual address.
- Initialize the virtual address by requesting File System. File System will open the file and store the file descriptor in the virtual address we got in the first step. Of course, it will allocate a page to the address first. 🤪
- Then, as we have the file descriptor allocate pages for the content of the file and map them to the 4 MB segment.
- At last, return the file descriptor number to the caller.
open
1 | int open(const char* path, int mode) |
Compared to opening a file, it would be much easier to close it.
close
1 | int close(int fdnum) |
Epilogue
A little verbose this time, I guess. 😵💫 But there are still some points that I didn’t cover… This is it… 😴
 WeChat
WeChat










